创建知识库&上传文件
创建知识库并上传文件大致分为以下步骤:
- 在 SenseFLow 工作台内点击创建知识库,填写知识库名称;
- 选择所需要的 Embedding 模型;
- 配置检索设置,确认创建;
- 从本地选择你需要上传的文件,等待分段嵌入;
- 选择分段与清洗模式,预览效果;
- 保存并处理,在应用内关联并使用 🎉
以下是各个步骤的详细说明:
创建知识库与知识库命名
在 SenseFLow 工作台的导航栏中点击知识库,点击“创建知识库” 进入创建向导,填写知识库名称。
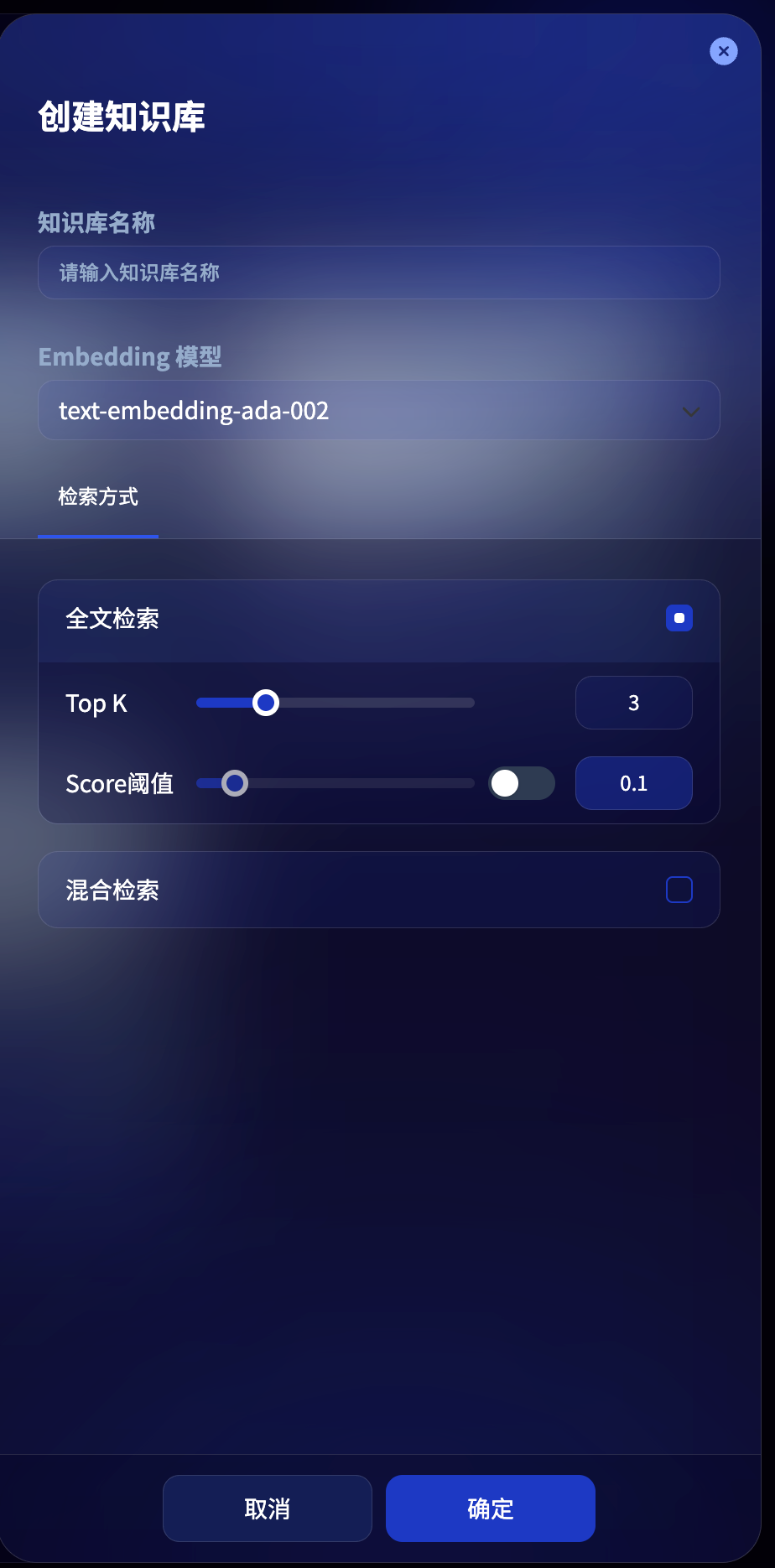
选择 Embedding 模型
Embedding是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。它可以将高维数据(如单词、短语或图像)映射到低维空间,提供一种紧凑且有效的表示方式。这种表示不仅减少了数据的维度,还保留了重要的语义信息,使得后续的内容检索更加高效。
Embedding模型是一种专门用于将文本向量化的大语言模型,它擅长将文本转换为密集的数值向量,有效捕捉语义信息。选择不同的Embedding模型会根据不同的任务需求和数据特点,找到最适合的模型来实现最优的文本表示。
配置检索方式
SenseFlow 提供以下两种检索方案:
- 全文检索
- 混合检索
全文检索
定义: 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
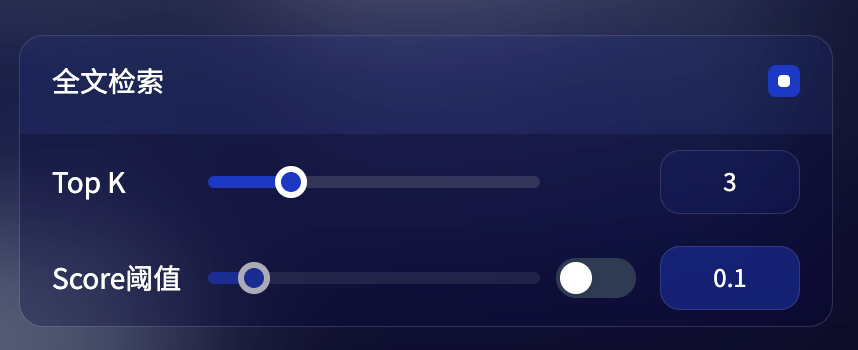
Top-K: 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。数值越高,预期被召回的文本分段数量越多。
Score 阈值: 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
混合检索
定义: 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”进行检索。
权重设置: 允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指�的是在知识库内进行向量检索(Vector Search)。
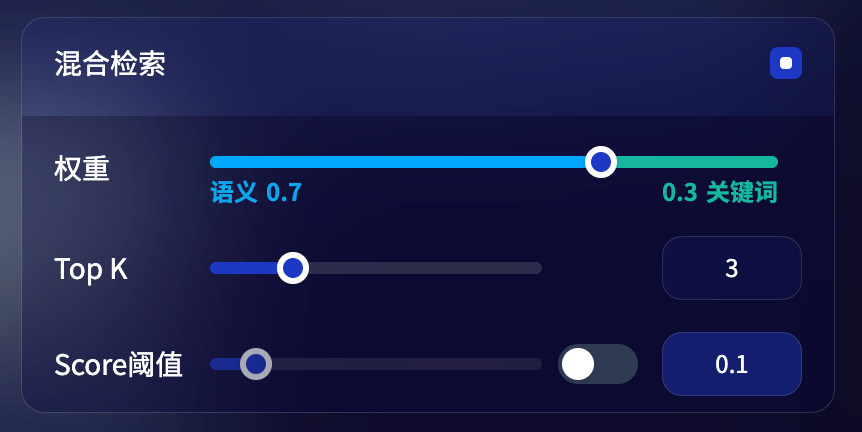
- 语义值为 1
仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。
- 关键词值为 1
仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
- 自定义关键词和语义权重
除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
指定检索设置后,你可以参考 召回测试/引用归属 查看关键词与内容块的匹配情况。
上传文件
- 拖拽或选中文件进行上传,单个文件的文件大小不能超过15MB。
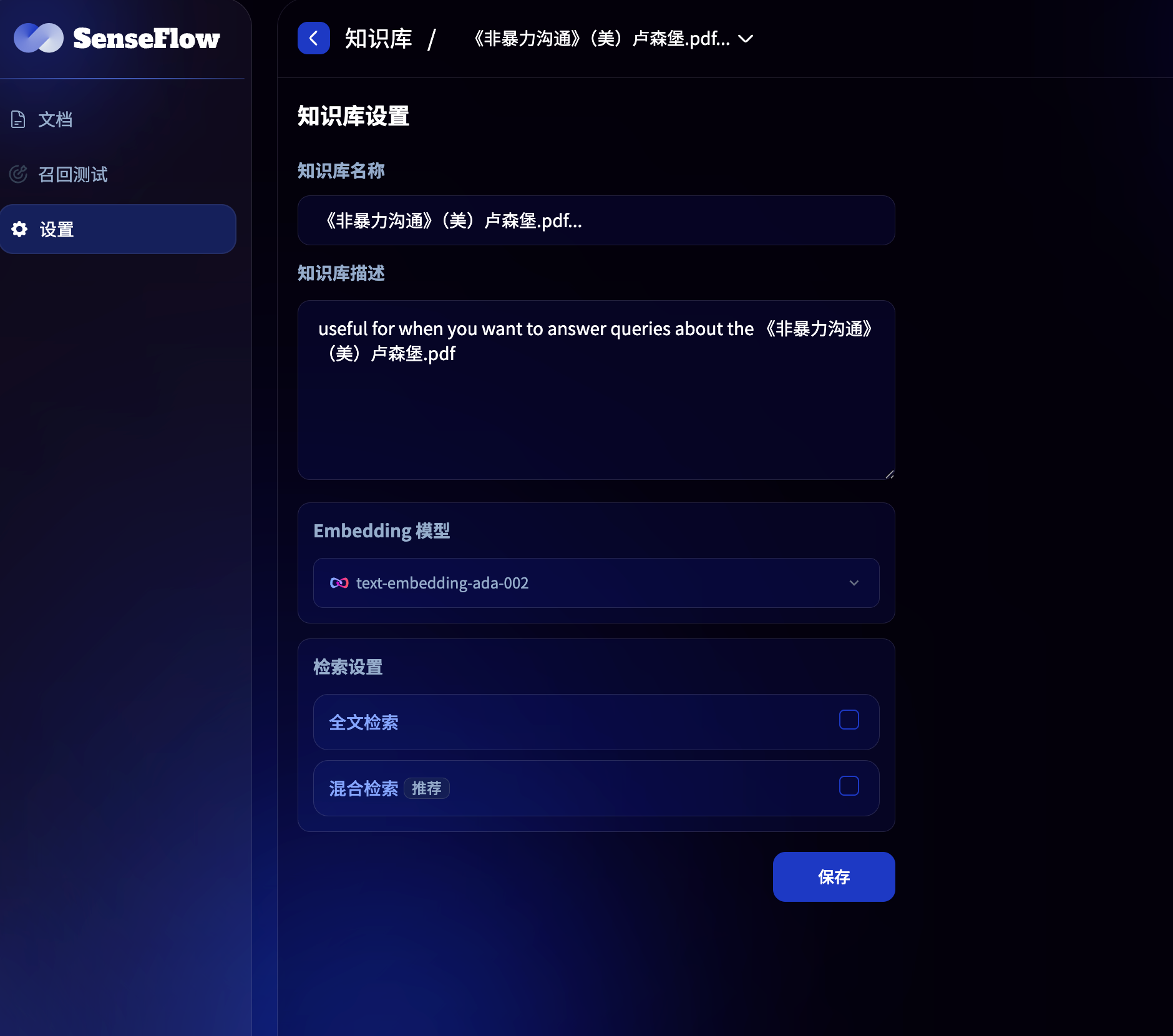
- 如果还没有准备好文档,��可以先创建一个空知识库;
选择分段与清洗策略
将内容上传至知识库后,需要先对内容进行分段与数据清洗,该阶段可以被理解为是对内容预处理与结构化。
-
什么是分段与清洗?
- 分段
大语言模型存在有限的上下文窗口,无法将知识库中的所有内容发送至 LLM。因此可以将整段长文本分段处理,再基于用户问题,召回与关联度最高的段落内容,即采用分段 TopK 召回模式。此外,将用户问题与文本分段进行语义匹配时,合适的分段大小有助于找到知识库内关联性最高的文本内容,减少信息噪音。
- 清洗
为了保证文本召回的效果,通常需要在将数据录入知识库之前便对其进行清理。例如,如果文本内容中存在无意义的字符或者空行,可能会影响问题回复的质量。
分段与清洗支持以下两种策略:
- 自动分段与清洗
- 自定义
自动分段与清洗
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,SenseFLow 将为你自动分段与清洗内容文件。

自定义
自定义模式适合对于文本处理有明确需求的进阶用户。在自定义模式下,你可以根据不同的文档格式和场景要求,手动配置文本的分段规则和清洗策�略。
分段规则:
- 分段标识符:指定标识符,系统将在文本中出现该标识符时分段。例如填写 (正则表达式中的换行符),文本换行时将自动分段;
- 分段最大长度:根据分段的文本字符数最大上限来进行分段,超出该长度时将强制分段。一个分段的最大长度为 1000 Tokens;
- 分段重叠长度:分段重叠指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%;
文本预处理规则:文本预处理规则可以帮助过滤知识库内部分无意义的内容。
- 替换连续的空格、换行符和制表符;
- 删除所有 URL 和电子邮件地址;
处理并完成
配置完上文所述的各项配置后,点击“保存并处理”即可完成知识库的创建。你可以参考 在应用内集成知识库,搭建出能够基于知识库进行问答的 LLM 应用。